用Python抓取谷歌搜索结果:實用指南
學習如何用 Python 抓取 Google 搜尋結果、保存數據進行分析,並判斷何時應改用 SERP API 取得更穩定的搜尋數據。







想用 Python 收集 Google 搜尋結果,通常有兩種做法。
第一種做法是直接請求 Google 結果頁,解析 HTML,然後提取你需要的連結或文字。這種方式適合學習、快速檢查和小型內部實驗。
第二種做法是在工作流需要穩定、可重複、易維護時使用 SERP API。這通常更適合排名追蹤、競品監控、AI 搜尋工作流、RAG 流程,或任何需要定期收集搜尋數據的任務。
這篇文章會展示兩種方式,並提供實用的 Python 範例。
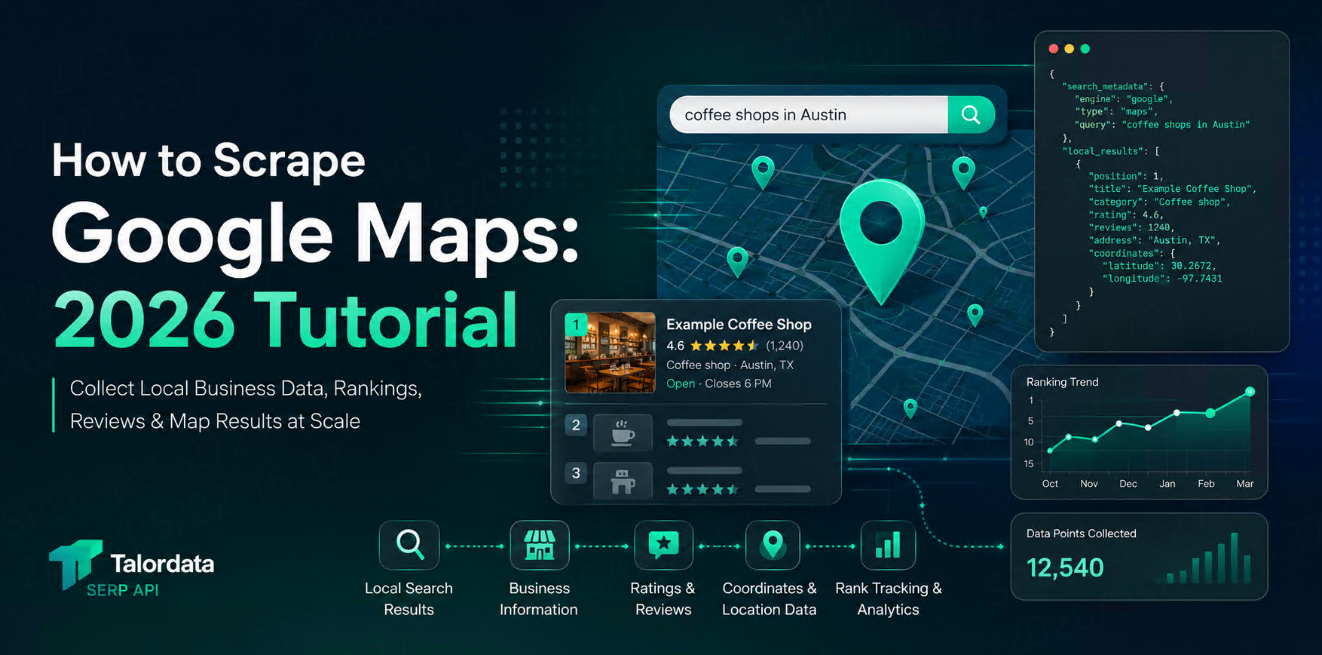
可以從 Google 搜尋結果中抓取哪些數據?
根據不同使用場景,Google SERP 數據可能包含:
自然結果標題
結果 URL
摘要文字
排名位置
廣告可見度
People also ask 結果
本地搜尋結果
新聞或圖片結果
相關搜尋
可供後續檢查的搜尋結果 HTML
不同方法能取得的結構化程度不同。直接解析 HTML 時,除非你持續維護 selector,否則通常只能提取基本連結和可見文字。SERP API 通常會提供更結構化的回應,但具體欄位取決於 API 供應商。
正式使用前,應先定義你真正需要什麼。排名追蹤工具可能只需要 keyword、position、URL、title 和 timestamp。AI Agent 則可能更需要 title、URL、snippet、source 和 retrieval time。
開始之前
如果只是做一個簡單 Python 測試,可以先安裝:
pip install requests beautifulsoup4
你會用到:
requests發送 HTTP 請求BeautifulSoup解析 HTMLcsv或json保存輸出結果
在大規模抓取任何網站之前,應先檢查適用法律、平台規則、robots.txt 指引,以及內部合規要求。搜尋結果頁經常變化,也不是為穩定 API 使用而設計的,所以直接爬取更適合學習或有限場景,除非你已經有清楚的維護計畫。
方法一:用 Python 直接抓取 Google 搜尋結果
下面是一個最小範例,用來請求 Google 搜尋頁並輸出部分可見文字。
import requests
from bs4 import BeautifulSoup
query = "best project management software"
url = "https://www.google.com/search"
params = {
"q": query,
"hl": "en",
"gl": "us"
}
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, params=params, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
print(soup.get_text(" ", strip=True)[:1000])
這不是正式生產用爬蟲,只是展示基本流程:
發送搜尋請求。
取得 HTML。
解析頁面。
檢查內容。
下一步可以嘗試提取連結。
import requests
from bs4 import BeautifulSoup
query = "best project management software"
url = "https://www.google.com/search"
params = {
"q": query,
"hl": "en",
"gl": "us"
}
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, params=params, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
results = []
for a_tag in soup.find_all("a"):
href = a_tag.get("href")
text = a_tag.get_text(" ", strip=True)
if not href or not text:
continue
results.append({
"text": text,
"url": href
})
for item in results[:10]:
print(item)
這段程式會返回很多連結,不一定都是乾淨的自然搜尋結果。有些可能是導航連結、跳轉連結,或其他 SERP 模組中的連結。
這就是直接爬取的主要限制:HTML 內容可以取得,但要把它整理成乾淨的 SERP 數據,還需要額外解析和清洗。
將搜尋結果保存為 CSV
對小型研究任務來說,把提取結果保存為 CSV 通常已經夠用。
import csv
import requests
from bs4 import BeautifulSoup
query = "best project management software"
url = "https://www.google.com/search"
params = {
"q": query,
"hl": "en",
"gl": "us"
}
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, params=params, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
rows = []
for a_tag in soup.find_all("a"):
href = a_tag.get("href")
text = a_tag.get_text(" ", strip=True)
if not href or not text:
continue
rows.append({
"query": query,
"text": text,
"url": href
})
with open("google_search_results.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["query", "text", "url"])
writer.writeheader()
writer.writerows(rows)
print(f"Saved {len(rows)} rows to google_search_results.csv")
這適合做數據檢查,但仍然無法解決排名位置、SERP 功能識別、本地化一致性或重複數據清洗。這些都需要你額外處理。
為什麼直接爬取會變難?
直接爬取很容易開始,但不容易長期穩定。
Google 搜尋結果頁可能隨時變化。今天有效的 selector,之後可能失效。不同查詢也可能觸發不同版面。產品查詢可能出現購物結果,本地查詢可能出現地圖,新聞相關查詢可能出現 Top Stories,資訊型查詢可能出現 People also ask。
搜尋結果也會受到以下因素影響:
國家
語言
裝置
位置
搜尋意圖
搜尋時間
對 SEO 和 AI 工作流來說,這些細節很重要。如果沒有保存查詢上下文,數據後續就很難比較。
至少應保存:
query
search engine
country 或 location
language
device
timestamp
raw response 或 raw HTML
一旦你需要定時收集、大量關鍵字、多地區結果或結構化輸出,這件事就不再只是寫 Python,而是維護一條搜尋數據管線。
方法二:用 Python 調用 SERP API
SERP API 讓你把搜尋參數發送到 API endpoint,並取得更結構化的搜尋結果。這可以減少 HTML 解析、本地化控制、重試和數據清洗方面的工作。
下面是一個通用 Python 範例,endpoint 和 API key 都使用占位符。
import requests
import json
endpoint = "YOUR_TALORDATA_SERP_API_ENDPOINT"
api_key = "YOUR_API_KEY"
params = {
"engine": "google",
"q": "best project management software",
"location": "United States",
"language": "en",
"device": "desktop"
}
headers = {
# Adjust this according to the provider's official authentication method.
"Authorization": f"Bearer {api_key}"
}
response = requests.get(endpoint, params=params, headers=headers, timeout=30)
response.raise_for_status()
data = response.json()
with open("google_serp_response.json", "w", encoding="utf-8") as file:
json.dump(data, file, ensure_ascii=False, indent=2)
print("Saved SERP response to google_serp_response.json")
具體的認證方式、參數名稱、支援值和回應結構取決於 API 供應商。如果使用 TalorData,建議先查看 SERP API 查詢參數文件,再進行正式串接。
當你需要的是可重複的搜尋數據,而不是一次性抓取頁面時,這種方式通常更實用。
如何處理 API 回應?
在查看文件和實際回應之前,不要預設 response structure。
比較安全的工作流是:
保存原始 API response。
檢查 JSON 結構。
決定應用需要哪些欄位。
只標準化真正需要的欄位。
每條數據都保存請求參數。
例如,檢查回應後,你可能會建立包含以下欄位的標準化數據表:
query
location
language
device
result type
title
URL
position
timestamp
具體欄位映射應以 API 供應商的官方 response format 為準。不要基於未確認的欄位建立正式邏輯。
什麼情況下可以直接爬取?
以下情況下,直接爬取可能已經足夠:
你正在學習搜尋頁如何運作
你只需要做快速內部測試
你只是人工檢查少量頁面
你不需要穩定的結構化輸出
你不打算大規模執行
如果產品每天都依賴穩定搜尋數據,直接爬取通常不是最佳選擇。
什麼情況下應該使用 SERP API?
當搜尋結果成為固定工作流的一部分時,SERP API 通常更合適。
常見場景包括:
SEO 排名追蹤
競品監控
廣告可見度檢查
本地搜尋分析
市場研究
AI Agent 搜尋上下文
RAG 外部數據檢索
內容情報工作流
比較 SERP API 時,建議關注這些實際細節:
支援哪些搜尋引擎
地區與語言控制能力
是否提供 JSON 和 HTML response
計費模式
文件品質
錯誤處理方式
請求成功規則
如果你的工作流需要 SEO、監控或 AI 搜尋場景中的結構化 SERP 數據,TalorData SERP API 可以作為其中一個評估選項。你也可以閱讀這篇相關文章:Google SERP API: Collect Real-Time Search Results at Scale。
總結
Python 是理解 Google 搜尋結果收集方式的好起點。簡單腳本可以幫你理解請求、HTML 解析和基本數據提取。
但如果目標是穩定 SERP 數據,直接爬取的維護成本會逐漸上升。真正困難的不是發送一次請求,而是在不同關鍵字、地區、裝置、版面和時間下保持工作流可靠。
對小型實驗來說,直接爬取可能沒問題。對正式 SEO 工具、AI Agent、RAG 系統或週期性市場研究來說,SERP API 通常是更乾淨的做法。
在選擇任何方案之前,先定義需要哪些參數,估算請求量,並確認成本如何隨關鍵字數量、地區數量和更新頻率增長。如果你正在評估 TalorData,可以查看 SERP API pricing page 和 SERP API 查詢參數文件。
FAQ
可以用 Python 抓取 Google 搜尋結果嗎?
可以。Python 可以請求 Google 搜尋結果頁,解析回傳的 HTML,並提取連結或可見文字。但直接爬取通常不穩定,因為頁面結構會變,結果也會受到地區、語言、裝置和搜尋意圖影響。
為什麼我的 Google 爬蟲會返回很多混亂連結?
Google 結果頁包含很多不屬於自然搜尋結果的連結,例如導航連結、跳轉連結、廣告、SERP 模組和其他頁面元素。你需要額外的過濾邏輯,才能從頁面噪音中分離出有用結果。
應該使用 BeautifulSoup 還是 SERP API?
BeautifulSoup 適合學習、檢查 HTML,或做小型實驗。如果你需要結構化輸出、可重複結果、地區控制、定時收集,或數據會支撐正式工作流,SERP API 通常更合適。
選擇 SERP API 前應該檢查什麼?
應檢查支援的搜尋引擎、地區與語言控制、回應格式、計費方式、文件品質、錯誤處理方式,以及 API 是否適合你的請求量和數據工作流。