
如何抓取 Google Maps:2026指南
了解如何抓取 Google Maps 數據,包括可收集的商家欄位、Python 基礎範例、常見挑戰,以及如何使用 Talordata SERP API 簡化 Google Maps 數據採集流程。
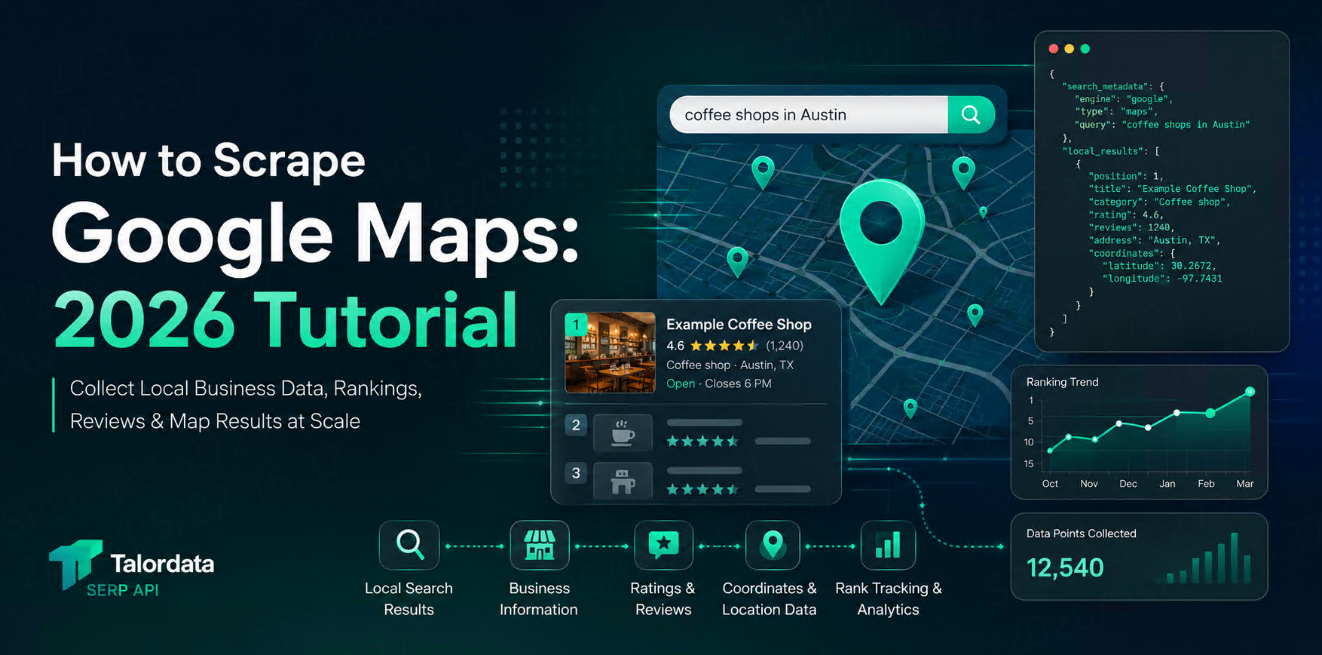







Google Maps 是最有價值的本地商家數據來源之一。
一次搜尋通常可以看到商家名稱、分類、評分、評論數、地址、網站、電話、營業時間,以及地圖結果中的排名位置。對本地 SEO 團隊、行銷代理商、銷售團隊和市場研究人員來說,這些數據很有價值,因為它們反映了使用者在搜尋本地服務時實際看到的結果。
例如:
coffee shops in Austin
dentist near me
best hotels in Singapore
car repair in Chicago
Italian restaurants in Brooklyn
如果你只是偶爾查一兩個關鍵字,手動搜尋就夠了。但如果你需要長期追蹤數百個關鍵字、不同城市或多個區域,手動檢查很快就會變得不可行。
這時候,Google Maps 數據抓取就有了實際價值。
可以從 Google Maps 抓取哪些數據?
Google Maps 結果會受到搜尋關鍵字、國家、語言、裝置、搜尋位置等因素影響。不同查詢下可見欄位不一定完全相同,但常見可收集數據包括:
欄位 | 範例 | 常見用途 |
商家名稱 | Joe’s Coffee House | 識別本地商家 |
商家分類 | Coffee shop | 按行業分類 |
評分 | 4.6 | 分析商家口碑 |
評論數 | 1,240 reviews | 判斷信任度與熱門程度 |
地址 | 123 Main St, Austin | 分析地理覆蓋 |
電話 | +1 xxx-xxx-xxxx | 銷售線索補充 |
網站 | example.com | 網站與網域匹配 |
營業時間 | Open ⋅ Closes 6 PM | 可用性研究 |
座標 | Latitude / longitude | 地圖分析與聚類 |
排名位置 | 1, 2, 3... | 本地 SEO 排名追蹤 |
對大多數業務場景來說,最重要的欄位通常是:
商家名稱
排名位置
商家分類
評分
評論數
地址
網站
電話
地理位置
不需要一開始就抓取所有欄位。更好的做法是先明確你的業務問題,再決定需要哪些數據。
為什麼要抓取 Google Maps 數據?
Google Maps 數據的價值,在於它可以呈現本地搜尋可見度。
同一家店可能在某個城市排名很好,但在另一個城市幾乎看不到。某家餐廳可能評論分數很高,但在重要關鍵字下排名並不理想。某個本地競爭對手可能在特定街區或服務區域長期占據靠前位置。
Google Maps 數據抓取可以把這些搜尋結果轉換成結構化數據,方便後續追蹤、比較和分析。
常見使用場景
1. 本地 SEO 排名追蹤
本地 SEO 團隊需要知道某個商家在目標關鍵字下的排名情況。
例如,一家牙科診所可能想追蹤:
dentist in Austin
emergency dentist Austin
family dentist near me
teeth whitening Austin透過定期收集 Google Maps 結果,SEO 團隊可以監控排名變化、比較競爭對手,並評估本地優化策略是否有效。
2. 競爭對手監控
Google Maps 結果可以直接反映某個本地市場中誰更有可見度。
你可以追蹤:
哪些競爭對手出現
它們的排名位置
它們的評分
它們的評論數
它們的商家分類
它們的位置
它們的網站這對代理商、連鎖品牌、本地服務商、飯店、餐廳、診所和零售品牌都很有用。
3. 銷售線索發掘
銷售團隊常用 Google Maps 數據尋找符合條件的本地商家。
例如:
沒有網站的餐廳
評論數較少的診所
線上形象較弱的本地商店
特定城市和分類下的商家
評分不錯但網站表現較弱的公司這些數據可以用於外呼銷售、CRM 補充、客戶分層和市場開發。
4. 市場研究
Google Maps 也可以用來分析本地市場密度。
例如,市場研究團隊可能想比較:
每個城市有多少健身房
哪些區域美容院更多
哪些街區餐飲競爭更密集
哪些本地分類有更高評論活躍度這類數據可用於選址分析、競爭研究和區域擴張。
Google Maps API 與 Google Maps 抓取有什麼不同?
在建立抓取工具之前,需要先理解 Google 官方 API 與 Google Maps 抓取之間的差異。
Google Places API 提供 Text Search、Nearby Search、Place Details 等官方能力。Text Search 可以根據文字查詢回傳地點資訊;Nearby Search 可以根據位置和地點類型查找附近地點。新版 Places API 也會使用 FieldMask 控制回傳欄位。
這種方式適合很多地點查詢和應用程式場景。
但 SEO 和市場情報團隊常常問的是另一類問題:
誰在這個本地關鍵字下排名?
哪些商家排在前面?
不同城市的結果有什麼差異?
哪些競爭對手在多個位置都出現?
使用者實際看到的本地搜尋結果是什麼樣?對這些場景來說,Google Maps SERP 數據通常比單純的地點查詢更有用。
開始之前:合規注意事項
Google Maps 相關數據的使用需要謹慎處理。
Google Maps Platform 條款對 Google Maps Content 的使用、批量下載、儲存和再利用有明確限制。不同使用場景的合規要求也可能不同。
本文僅用於技術和教育說明。在收集、儲存或使用 Google Maps 相關數據之前,建議先檢查 Google 官方最新條款、所在地法律法規、隱私要求,以及你所在公司的內部合規政策。
對於生產環境,很多團隊更傾向於使用結構化 SERP 數據服務,因為它們希望用更可控、更穩定的方式獲取搜尋結果數據,而不是長期維護脆弱的瀏覽器自動化流程。
如何用 Python 抓取 Google Maps
一個基礎 Google Maps 抓取流程通常包括:
1. 開啟 Google Maps 搜尋 URL
2. 等待頁面載入
3. 滾動結果面板
4. 擷取可見商家列表數據
5. 將文字解析成結構化欄位
6. 匯出為 JSON 或 CSV
因為 Google Maps 是高度動態、依賴 JavaScript 的頁面,所以使用 Playwright 這類瀏覽器自動化工具,通常比單純 HTTP 請求更實際。
下面是一個簡單的教學範例。
Step 1:建立 Python 專案
建立數據夾:
mkdir google-maps-scraper
cd google-maps-scraper
python -m venv venv
啟用環境:
# macOS / Linux
source venv/bin/activate
# Windows
venv\Scripts\activate
安裝 Playwright:
pip install playwright
python -m playwright install
建立檔案:
touch scraper.py
Step 2:開啟 Google Maps 搜尋頁
在 scraper.py 中加入:
import asyncio
from playwright.async_api import async_playwright
SEARCH_URL = "https://www.google.com/maps/search/coffee+shops+in+Austin"
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page(locale="en-US")
await page.goto(SEARCH_URL, wait_until="domcontentloaded", timeout=60000)
await page.wait_for_timeout(5000)
await browser.close()
asyncio.run(main())
執行:
python scraper.py
這段程式會開啟 Google Maps,並載入一個本地搜尋結果頁。
測試時建議保留 headless=False,方便觀察瀏覽器實際操作。
Step 3:滾動結果面板
Google Maps 不會一次載入所有商家。通常需要滾動左側結果面板,才會逐步載入更多結果。
加入以下函式:
async def scroll_results(page, scroll_times=8):
feed = page.locator('div[role="feed"]')
for _ in range(scroll_times):
await feed.evaluate("(el) => el.scrollBy(0, el.scrollHeight)")
await page.wait_for_timeout(1500)
這會多次滾動結果面板。
在實際專案中,你可能還需要判斷何時已經沒有新結果載入。
Step 4:擷取商家列表
Google Maps 結果卡片可能會變化,所以 selector 可能失效。初始做法可以先收集卡片文字和 accessible label。
加入:
async def extract_listings(page):
cards = page.locator('div[role="article"]')
count = await cards.count()
results = []
for i in range(count):
card = cards.nth(i)
try:
name = await card.get_attribute("aria-label")
text = await card.inner_text(timeout=3000)
results.append({
"position": i + 1,
"name": name,
"raw_text": text
})
except Exception:
continue
return results
這還不是完美數據集,但可以作為原始數據擷取層。
Step 5:匯出 JSON
完整程式如下:
import asyncio
import json
from playwright.async_api import async_playwright
SEARCH_URL = "https://www.google.com/maps/search/coffee+shops+in+Austin"
async def scroll_results(page, scroll_times=8):
feed = page.locator('div[role="feed"]')
for _ in range(scroll_times):
await feed.evaluate("(el) => el.scrollBy(0, el.scrollHeight)")
await page.wait_for_timeout(1500)
async def extract_listings(page):
cards = page.locator('div[role="article"]')
count = await cards.count()
results = []
for i in range(count):
card = cards.nth(i)
try:
name = await card.get_attribute("aria-label")
text = await card.inner_text(timeout=3000)
results.append({
"position": i + 1,
"name": name,
"raw_text": text
})
except Exception:
continue
return results
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page(locale="en-US")
await page.goto(SEARCH_URL, wait_until="domcontentloaded", timeout=60000)
await page.wait_for_timeout(5000)
await scroll_results(page)
results = await extract_listings(page)
with open("google_maps_results.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
await browser.close()
asyncio.run(main())
執行後會得到:
google_maps_results.json
輸出可能像這樣:
[
{
"position": 1,
"name": "Example Coffee Shop",
"raw_text": "Example Coffee Shop\n4.6\n(1,240)\nCoffee shop\nAustin, TX\nOpen ⋅ Closes 6 PM"
}
]
Step 6:解析原始文字
原始文字有用,但大多數團隊需要結構化欄位。
可以先寫一個簡單 parser:
import re
def parse_listing(raw_text):
lines = [line.strip() for line in raw_text.split("\n") if line.strip()]
rating = None
review_count = None
for line in lines:
if re.match(r"^\d\.\d$", line):
rating = line
review_match = re.search(r"\(([\d,]+)\)", line)
if review_match:
review_count = review_match.group(1).replace(",", "")
return {
"lines": lines,
"rating": rating,
"review_count": review_count
}
這只是起點。
真實 Google Maps 頁面會因國家、語言、商家分類和頁面布局而變化。如果你需要穩定輸出,就需要更完整的解析規則、測試樣本、備援邏輯和監控機制。
為什麼 Google Maps 抓取很難?
建立一個簡單 scraper 不難。
難的是讓它長期穩定。
1. Google Maps 是動態頁面
Google Maps 會逐步載入結果。有些數據要滾動後才出現,有些細節需要點擊商家卡片才看得到。
你的 scraper 可能需要處理:
滾動
等待
點擊
懶載入
詳情面板
不同結果布局
複雜度會很快上升。
2. Selector 可能失效
Google Maps 頁面不是為數據抓取設計的穩定 API。
class name、DOM 結構和結果布局都可能變化。今天可用的 selector,之後可能失效。
這會帶來持續維護成本。
3. 本地結果對位置非常敏感
同一個關鍵字,可能因為以下因素返回不同結果:
國家
城市
座標
語言
裝置
搜尋上下文
對本地 SEO 追蹤來說,這非常關鍵。
如果位置設定不一致,排名數據就不可靠。
4. 解析很容易變得混亂
Google Maps 列表文字不一定乾淨。
一個商家結果中可能包含評分、評論數、分類、地址、價格、營業時間、服務選項或短標籤,而且順序不固定。
你可能需要為不同數據寫規則:
評分
評論數
地址
電話
營業時間
商家分類
暫停營業狀態
廣告結果
支援的市場越多,解析成本越高。
5. 大規模瀏覽器自動化成本高
跑一次本地 scraper 很簡單。
但如果要跨城市、跨關鍵字、大批量定期抓取,就完全不同。
你需要處理:
瀏覽器實例
超時
失敗任務
數據校驗
重複商家
定時任務
數據儲存
監控
錯誤處理
這也是很多團隊最後選擇 SERP API 的原因。
更好的方式:使用 Google Maps SERP API
如果只是測試,瀏覽器 scraper 可以用。
如果是長期業務流程,SERP API 通常更容易維護。
你不需要打開 Google Maps、滾動頁面、解析混亂 HTML,而是直接發送 API 請求,取得結構化數據。
典型流程如下:
1. 準備關鍵字
2. 準備目標位置
3. 發送 API 請求
4. 接收結構化 JSON
5. 儲存結果
6. 分析排名、競品與商家欄位
Talordata SERP API 面向 Google 與其他主要搜尋引擎的結構化搜尋結果數據,支援地理位置定向 SERP、JSON / HTML 回傳格式、Maps 搜尋類型,以及按成功請求計費的模式。
這對需要重複收集本地搜尋數據、但不想長期維護脆弱抓取基礎設施的團隊更友好。
Talordata SERP API 工作流程範例
一個 Google Maps 數據流程可能像這樣:
Keyword: coffee shops
Location: Austin, Texas, United States
Search type: Maps
Language: English
Output: JSON
請求結構可能如下:
curl -X POST "https://<talordata-serp-api-endpoint>" \
-H "Authorization: Bearer $TALORDATA_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"engine": "google",
"type": "maps",
"q": "coffee shops in Austin",
"location": "Austin, Texas, United States",
"gl": "us",
"hl": "en",
"device": "desktop",
"output": "json"
}'
具體 endpoint 和參數應以 Talordata 後台或 API 文件為準。
結構化回傳可能包含:
{
"search_metadata": {
"engine": "google",
"type": "maps",
"query": "coffee shops in Austin",
"location": "Austin, Texas, United States"
},
"local_results": [
{
"position": 1,
"title": "Example Coffee Shop",
"category": "Coffee shop",
"rating": 4.6,
"reviews": 1240,
"address": "Austin, TX",
"phone": "+1 xxx-xxx-xxxx",
"website": "https://example.com",
"hours": "Open ⋅ Closes 6 PM",
"coordinates": {
"latitude": 30.2672,
"longitude": -97.7431
}
}
]
}
這種數據比原始頁面文字更容易接入數據庫、看板、CRM、SEO 報表或內部分析工具。
使用 Talordata SERP API 的 Python 範例
生產流程中的程式可以更簡潔:
import os
import json
import requests
API_KEY = os.getenv("TALORDATA_API_KEY")
ENDPOINT = "https://<talordata-serp-api-endpoint>"
payload = {
"engine": "google",
"type": "maps",
"q": "coffee shops in Austin",
"location": "Austin, Texas, United States",
"gl": "us",
"hl": "en",
"device": "desktop",
"output": "json"
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
response = requests.post(
ENDPOINT,
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status()
data = response.json()
with open("talordata_google_maps_results.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
這樣一來,團隊可以把精力放在數據分析和業務流程,而不是瀏覽器自動化維護。
應該追蹤哪些數據?
不要為了抓數據而抓數據。
先確定場景,再選欄位。
本地 SEO 場景
建議追蹤:
關鍵字
位置
商家名稱
排名位置
評分
評論數
分類
時間戳這可以幫你追蹤本地排名變化。
競品監控場景
建議追蹤:
競品名稱
排名位置
分類
評分
評論數
地址
網站
電話這可以幫你比較不同城市或服務區域中的可見競爭對手。
銷售線索場景
建議追蹤:
商家名稱
分類
網站
電話
評分
評論數
地址
城市這可以幫你按銷售潛力篩選商家。
市場研究場景
建議追蹤:
分類
城市
座標
評論量
商家密度
平均評分這可以幫你比較本地市場,找出競爭密集或供給不足的區域。
結語
Google Maps 數據可以幫助團隊理解本地搜尋可見度、競爭強度、商家密度和市場機會。
簡單的 Python scraper 可以幫你理解流程。但在真實業務中,Google Maps 抓取會受到動態頁面、selector 變化、位置敏感性和解析複雜度影響。
Talordata SERP API 提供了更實用的方式,幫助團隊跨關鍵字和位置收集結構化搜尋結果數據。與其把大量時間花在維護抓取基礎設施上,不如把重點放在分析、報表和決策上。
一個好的流程應該是:
定義目標關鍵字
選擇位置
收集結構化結果
穩定儲存數據
追蹤變化
轉化為行動這樣,Google Maps 數據就不只是一份商家清單,而是一套本地搜尋情報系統。
FAQ
可以抓取 Google Maps 嗎?
技術上可以。你可以使用瀏覽器自動化工具開啟 Google Maps、執行搜尋、滾動結果面板,並擷取可見商家數據。不過,Google Maps 數據使用涉及條款與合規問題,收集和儲存數據前應先檢查官方政策和適用法律。
Google Maps 結果中可以收集哪些數據?
常見欄位包括商家名稱、分類、評分、評論數、地址、網站、電話、營業時間、座標和排名位置。具體可用欄位會因查詢、位置、語言、裝置和頁面布局而不同。
Google Places API 和 Google Maps 抓取有什麼不同?
Google Places API 是官方地點數據 API,適合 Text Search、Nearby Search、Place Details 等場景。Google Maps 抓取或 SERP 型數據收集,更關注使用者在特定關鍵字和位置下實際看到的本地搜尋結果、排名和可見度。
什麼時候應該使用 Google Maps SERP API?
當你需要跨多個關鍵字、城市、語言或裝置定期收集本地搜尋數據時,就適合使用 Google Maps SERP API。常見場景包括本地 SEO 追蹤、競品監控、銷售線索發掘和市場研究。
Talordata 可以幫助收集 Google Maps 數據嗎?
可以。Talordata SERP API 支援結構化 SERP 數據、地理位置定向搜尋結果、JSON / HTML 回傳格式和 Maps 搜尋類型,適合需要可擴展本地搜尋數據流程的團隊。







